Video Understanding by Design:
How Datasets Shape Video Models
Abstract
Research in video understanding has advanced rapidly, driven by increasingly diverse datasets and more powerful model architectures. While existing surveys often organize progress by tasks, benchmarks, or model families, they provide limited insight into why particular architectures emerged and succeeded.
This survey adopts a dataset-centric perspective: dataset structure shapes model design. Motion complexity, temporal span, compositional hierarchy, multi-agent interaction, and multimodal richness impose distinct learning challenges. These pressures naturally give rise to inductive biases for viewpoint robustness, temporal ordering, long-range dependency modeling, relational reasoning, and cross-modal alignment.
Dataset Properties
Motion, duration, interaction, composition, and modality define the learning signal.
Inductive Biases
Models favor different invariances and evidence patterns depending on the data regime.
Architectural Response
Model families can be understood as responses to evolving dataset requirements.
MotionFormer
Dataset-induced representational biases (final block)

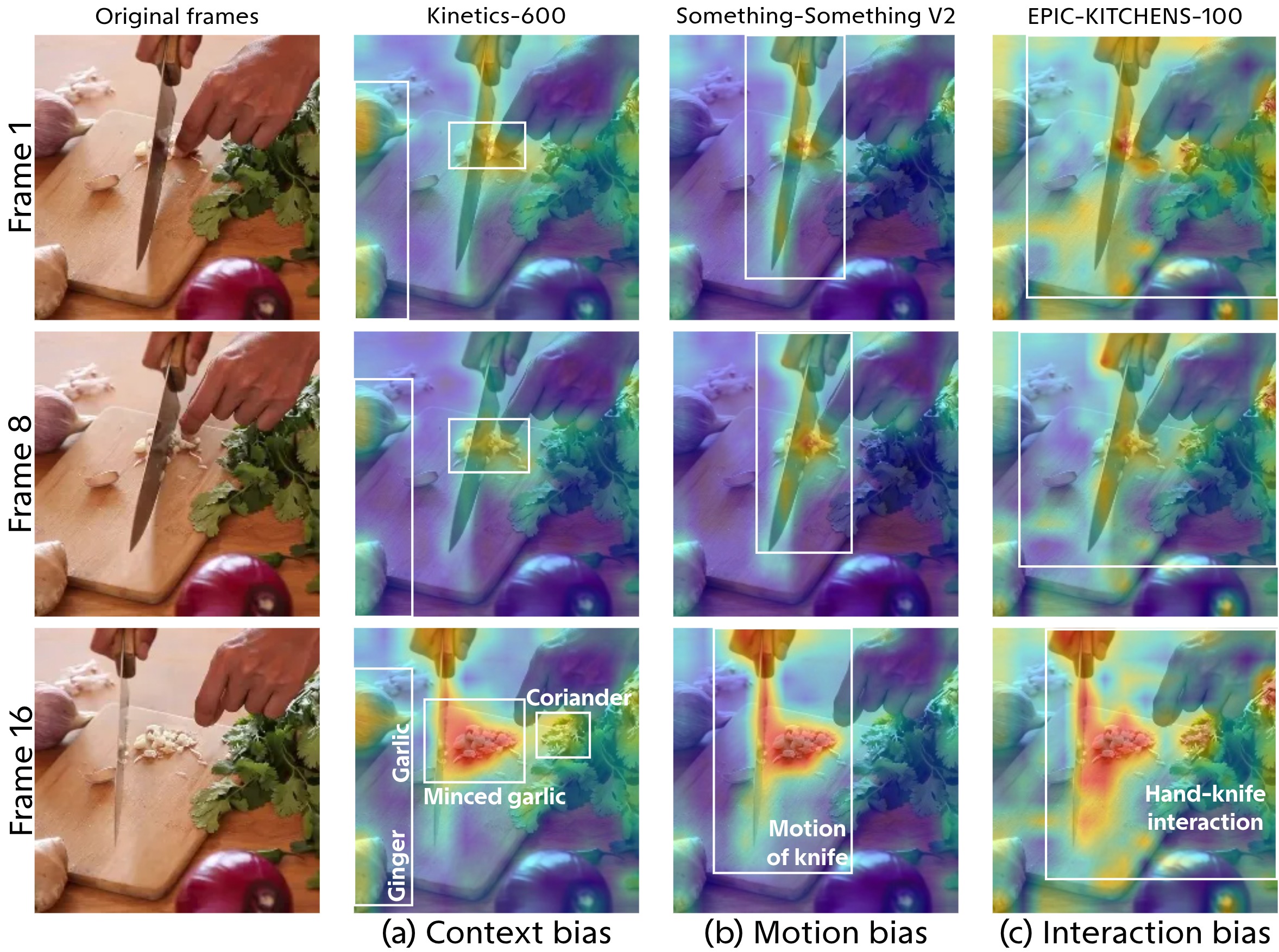
Original Frames
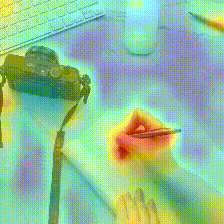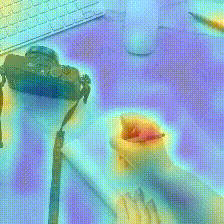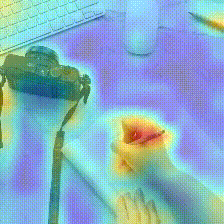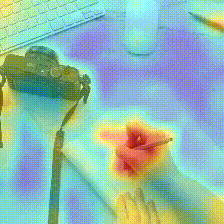
Kinetics-400
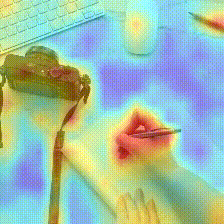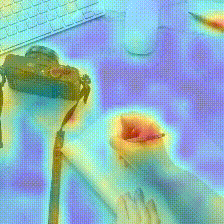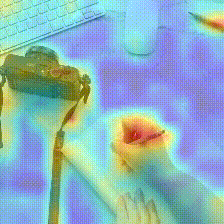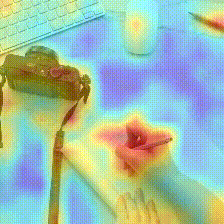
Kinetics-600

Something-Something V2

EPIC-KITCHENS-100
Dataset-induced biases across network depth (pre-training on Something-Something V2)
TimeSformer
Dataset-induced representational biases (final block)

Original Frames
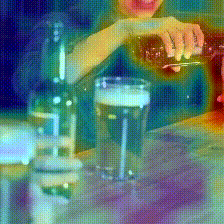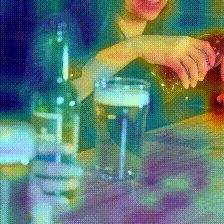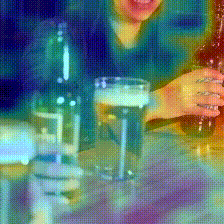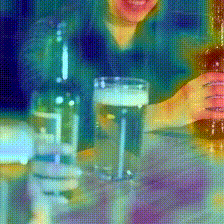
Kinetics-400
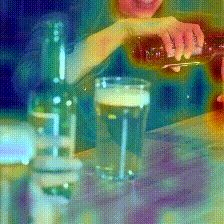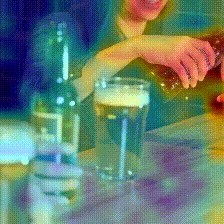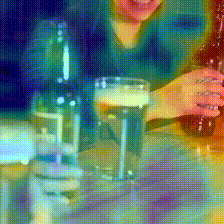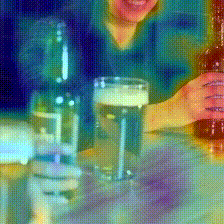
Kinetics-600
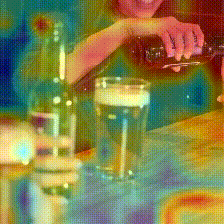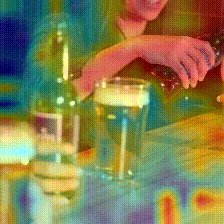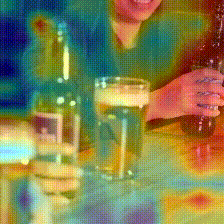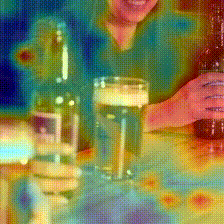
Something-Something V2
Dataset-induced biases across network depth (pre-training on Something-Something V2)
Playground
Choose two model/pretrain/video groups. Every block is shown in order.
Takeaway
BibTeX
Please use the following BibTeX entry to cite our work if you find it useful in your research.
@article{wang2026video,
title={Video Understanding by Design: How Datasets Shape Video Models},
author={Wang, Lei and Li, Syuan-Hao and Koniusz, Piotr and Gao, Yongsheng},
journal={arXiv preprint arXiv:2509.09151},
year={2026}
}